Tseng, Y. H. and Ding, C. (2008), 'Efficient parallel I/O in Community Atmosphere Model (CAM)', International Journal of High Performance Computing Applications 2008, 22, 206, DOI: 10.1177/1094342008090914
![]()
High resolution Century- or millennium-long global climate simulations using the NCAR Community Climate System Model (CCSM) generate tremendous amount of data. Efficient I/O is a crucial factor for such large-scale simulations on massively parallel machines, but CCSM currently uses sequential I/O through a single processor. This will soon become a major bottleneck for even higher resolution simulations. Here we implement the Parallel NetCDF (PnetCDF) with ZioLib algorithm in the Community Atmosphere Model (CAM), a component of CCSM, to facilitate efficient and flexible parallel I/O.
In distributed memory parallel environment, most applications rely on a serial I/O strategy, where the global array is gathered on a single processor and then written out to a file. The I/O performance with this approach is largely limited by single PE I/O bandwidth. Even when parallel I/O is used, satisfactory parallel scaling is not always observed. Parallel I/O rates can depend sensitively on parallel decompositions. The current approach, combining the features of PnetCDF and ZioLib, ensures the flexibility and the maximum I/O rate for all physical decompositions. Our tests show that this approach greatly Improves the CAM I/O performance and removes the I/O bottleneck. The maximum speed-up is roughly scaled with the increasing domain size.
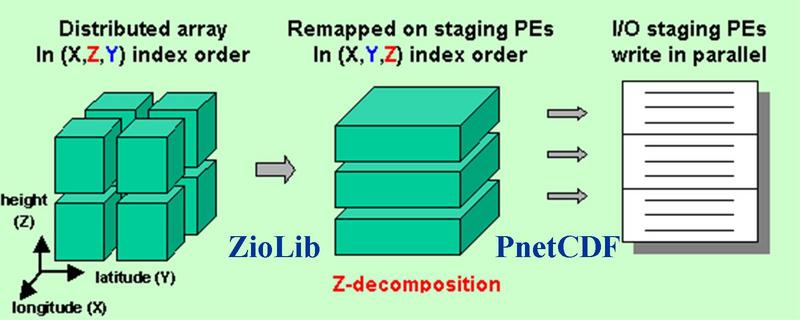
In climate models a field in CPU resident memory is often in one index order but stored in a disk file in another order. For example, history data for NCAR's Community Atmosphere Model (CAM) dynamic variables are in (longitude, height, latitude) order but must be written out to a file in (longitude, latitude, height) order. Changing index orders complicates a parallel I/O implementation and slows down I/O.
NetCDF is a simple and widely used file format. The PnetCDF interface facilitates an efficient
parallel I/O to access a single netCDF file. However, the I/O rate may not be optimal depending on
the array's index order and the results may not be consistent with the serial I/O. On the other hand, ZioLib can flexibly remap the distributed array and output data in parallel. Thus, our strategy is to
remap a distributed field into a Z-decomposition on a subset of processors ("I/O staging processors")
using the ZioLib algorithm, and then write to a disk file using PnetCDF (see below figure). In this Z-decomposition,
the data layout of the remapped array on the staging processors' memory is the same as on disk, thus only block data
transfer occurs during parallel I/O, achieving maximum efficiency.
Input file can no longer be downloaded here.
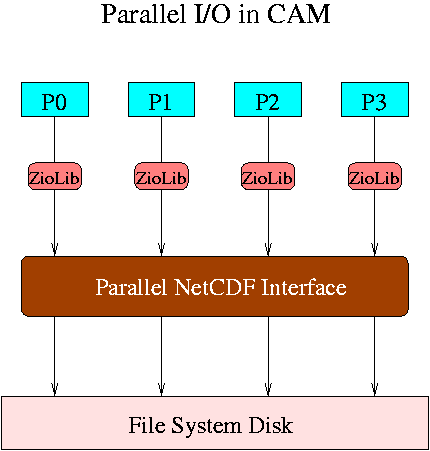
In the current CAM, a field in CPU resident memory is in one index order but is stored in a disk file in another order. To optimize the I/O performance, we have implemented the PnetCDF with ZioLib algorithm on CAM3.0 and CAM3.1 history I/O and compared with the serial netCDF I/O (i.e., one staging processor) using 2 to 512 MPI tasks on the IBM SP at LBNL/NERSC. All dynamic cores (Eulerian, Semi-Lagrangian and Finite Volume) are tested. The parallel implementation in CAM is illustrated below. P0-P4 are the I/O stage processors. In the current version, we use all nodes to obtain the maximum performance. See our poster presentation for further information and other benchmark tests.
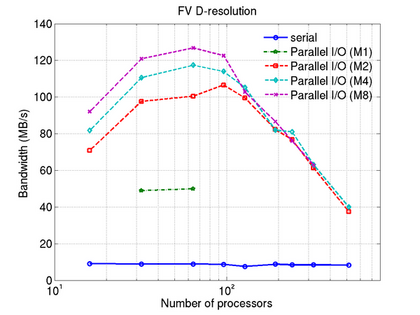
The number of processors (tasks) v.s. Bandwidth.
The curves represent the number of processors in a MPI_task (M4 refers to 4 processor per MPI_task).